A New Emerging Technologies framework for the post-roadmap era: The future isn’t invented in a boardroom; it leaks in through the cracks of human behavior.
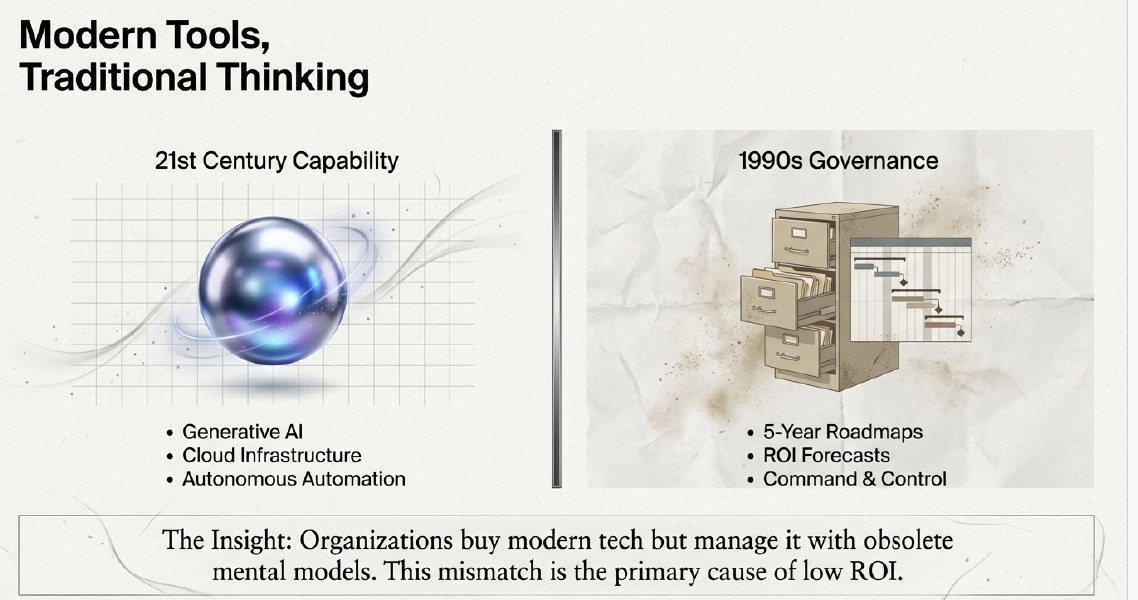
If you look at the modern enterprise, you will see a glaring paradox. We are currently witnessing a massive collision in the technology space. On one hand, organizations are aggressively acquiring 21st-century capabilities: Generative AI, autonomous automation, and cloud infrastructure.

On the other hand, we are attempting to govern these fluid, hyper-fast technologies using 1990s governance models: 5-year roadmaps, rigid ROI forecasts, and hierarchical “Command & Control” structures
The Insight: Organizations buy modern tech but manage it with obsolete mental models. This mismatch is the primary cause of low ROI.
It is time to admit that we are suffocating modern tools with dead processes. We need a new framework.
Flipping the Arrow of Causality
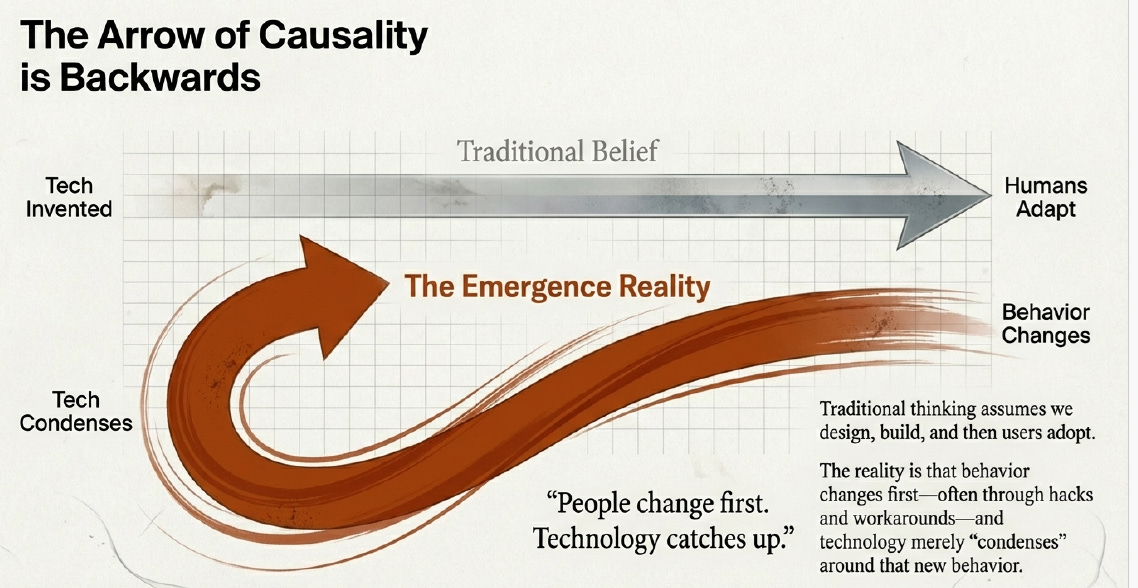
The core of this obsolescence lies in a fundamental misunderstanding of how innovation happens. We have the “Arrow of Causality” backwards.
The Traditional Belief: We design technology, we build it, and then users adopt it5555.
The Emergence Reality: Behavior changes first—often through hacks and workarounds—and technology merely “condenses” around that new behavior.
We act as if technology is invented in R&D labs and progress is linear. In reality, humans adapt first. “People change first... technology catches up”.
The 10 Dimensions of Emergence
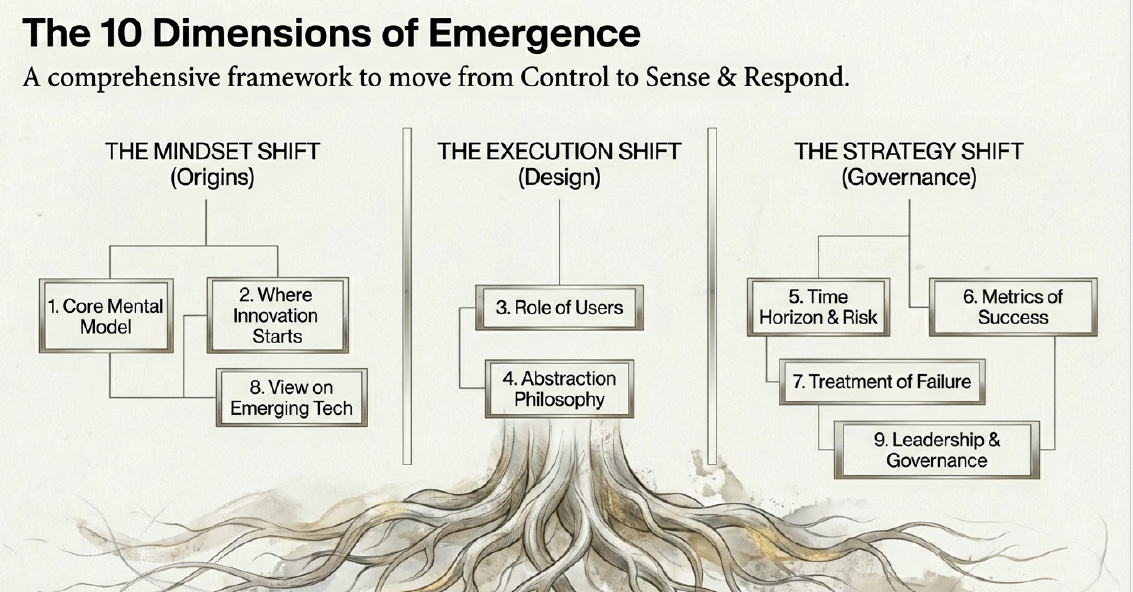
To fix this, we need a comprehensive framework that moves us from “Control” to “Sense & Respond”. This isn’t just a software update; it is a root-and-branch restructuring of the organization across three shifts:
The Mindset Shift (Origins): Changing our core mental models and where we look for innovation.
The Execution Shift (Design): Rethinking the role of users and our philosophy on abstraction.
The Strategy Shift (Governance): Altering our time horizons, metrics of success, and treatment of failure.
Shift 1: Innovation is Observed, Not Invented
If we accept that behavior leads technology, our R&D approach must change.
Traditional View: Technology is invented. Progress is linear. We look for Prototypes.
Emergent View: Technology “condenses” from real-world behavior. Progress is punctuated. We look for Workarounds.
The Cloud Case Study:
Traditional R&D asked, “How do we build a better Virtual Machine?”.

Emergent observation asked, “Why are developers writing scripts to skip the IT department?”.
The “cloud” wasn’t a product launch; it was the condensation of rebellious developer behavior.
Shift 2: Users are Co-Creators, Not Adopters
We have spent decades treating users as students to be trained, trying to “hide complexity” from them. The Emergence Inversion flips this.
Users are signal generators.

True modernization doesn’t remove complexity; it relocates it away from the human.
Philosophy: Abstract ‘friction’, not ‘complexity’.
Example: Cloud didn’t remove complexity—it moved it away from humans so the User Experience could be frictionless.
Shift 3: Risk is Reduced by Speed, Not Planning
This is the hardest pill for the Board to swallow. The traditional risk management cycle (Predict → Build → Launch) views failure as waste and relies on ROI projections.

But in a complex system, the “Launch” is the moment of highest risk.
The Modern Risk Equation:
Process: Observe → Prototype → Amplify
Metric: Adoption Velocity (not ROI forecasts)
Mentality: Failure is Signal
By utilizing continuous probing, you keep risk low. If you wait for a measurable ROI forecast, the emergence is already over.
Leadership: From ‘Control’ to ‘Sense’
The “Governance Gap” usually isn’t a failure of vision; it is a failure of late sensing.
Strategy can no longer be a static document filed in a drawer. It must become a living system of distributed intelligence. For this to work, psychological safety is non-negotiable.

“You must be safe to fail in order to generate the signal required to succeed.”
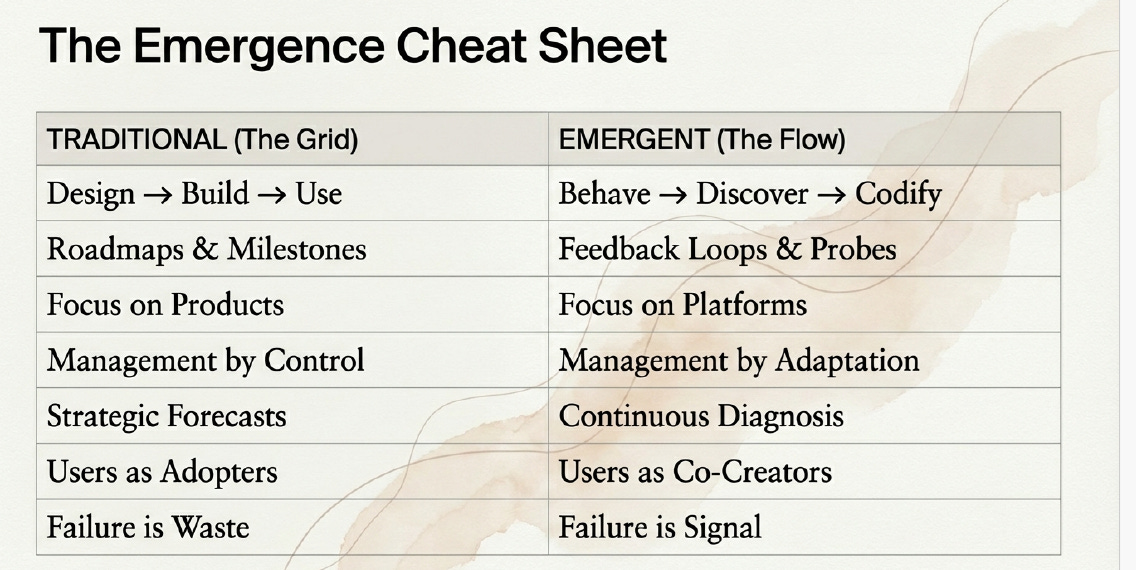
The Emergence Cheat Sheet
How do you know if you are operating in “The Grid” (Traditional) or “The Flow” (Emergent)?
The Verdict
The future is not “disrupted” in a noisy explosion. It leaks in quietly through human behavior—until systems that refuse to adapt suddenly collapse.

The advice for the modern executive is simple:
Stop road mapping. Start sensing.
#TheEmergenceInversion #DigitalTransformation #FutureOfWork #AgileStrategy #Innovation #GenerativeAI #ManagementTheory #SenseAndRespond